本文围绕“欧陆平台高可用集群设计与优化策略研究及实践探索”进行深入探讨,首先阐明了高可用集群的重要性和基本概念。接着,从架构设计、负载均衡、故障恢复及监控管理四个方面详细分析了实现高可用性所需的关键策略和技术。在此过程中,结合实际案例,探讨了在不同环境下的应用效果与优化方法,为读者提供系统而全面的理解。同时,通过总结归纳,将各部分内容串联起来,以便为后续的研究和实践提供参考依据。
1、高可用集群架构设计
高可用集群架构设计是确保系统稳定运行的基础,它涉及到多个节点之间的协作关系。首先,需要明确集群中各个节点的角色分配,包括主节点、备份节点以及客户端接入等。这种角色分配可以有效减轻单一节点的负担,提高整个系统的处理能力和容错能力。
其次,在架构设计中应考虑冗余机制。通过部署多台相同配置的服务器,可以在某一节点出现故障时,其他节点能够无缝接管其工作。冗余不仅增加了系统的可靠性,也为后期维护和升级提供了便利,有助于减少停机时间。
最后,高可用集群还需考虑网络拓扑结构。合理配置网络架构,将各个节点通过高速网络连接,可以减少数据传输延迟,提高响应速度。同时,选择合适的数据同步方案,如双向复制或多主模式,以确保数据的一致性和实时性,是提升集群性能的重要举措。
2、负载均衡策略
负载均衡是实现高可用性的关键环节之一,其目的是将用户请求合理分配到各个服务器上,从而避免某一台服务器因过载而崩溃。常见的负载均衡策略包括轮询、加权轮询以及最少连接数等,这些策略根据实际需求选择实施。
除了传统的方法,现在也越来越多地采用智能算法进行动态负载均衡。例如,通过实时监测每台服务器的性能指标(如CPU使用率、内存占用等),自动调整请求分发策略,以优化资源利用率,实现更好的用户体验。
此外,还需要考虑如何处理会话粘滞问题。在一些应用场景下,用户在访问过程中可能需要保持与特定服务器的一致性,因此可以通过Session持久化技术来解决这一问题,从而进一步提升系统稳定性。
3、故障恢复机制
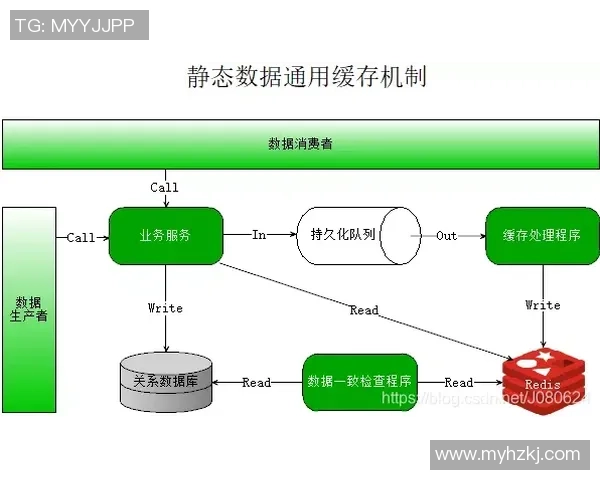
故障恢复是高可用集群不可或缺的一部分。一旦发生硬件故障或软件异常,快速且有效地恢复服务至关重要。首先,应建立完善的数据备份机制,包括定期全量备份和增量备份,以便在发生故障时能够迅速还原数据。
其次,要实现自动化故障检测与切换。当某一节点无法正常工作时,系统应能够即时发现并自动将流量切换到欧陆平台健康节点,这样可以最大限度地降低用户受到影响的可能性。这一过程通常依赖于监控工具及相应的软件支持。

最后,定期进行灾难演练也是提高故障恢复能力的重要手段。通过模拟各种可能出现的问题场景,使团队熟悉应对流程,从而在真正发生故障时能够快速反应,有效减少业务损失。
4、监控管理体系
监控管理体系是保障高可用性的另一重要组成部分,其核心目标是实时掌握系统运行状态,并及时采取措施避免潜在风险。首先,应建立全面的信息采集机制,对所有关键指标进行实时监控,包括CPU使用率、内存占用情况以及网络延迟等,以确保第一时间发现问题。
其次,需要设置合理的告警机制。一旦某项指标超过预设阈值,即刻通知相关人员,以便他们能够尽快采取措施。此外,还要制定详细的问题处理流程,使得团队成员能迅速响应并解决问题,从而降低事故对业务造成影响的可能性。
最后,对于历史数据进行分析与总结,也是监控管理的重要任务。通过对以往事件记录进行回顾,可以发现潜在的问题趋势,并据此优化现有策略,为未来的发展打下坚实基础。
总结:
综上所述,“欧陆平台高可用集群设计与优化策略研究及实践探索”涵盖了从架构设计到监控管理等多个方面,通过综合运用各种技术手段,实现了信息系统稳定、高效、安全地运行。这不仅提高了用户满意度,也为企业持续发展奠定了良好基础。
未来,我们希望能继续深入研究新的技术和方法,不断完善现有体系,以适应日益变化的信息技术环境。同时,加强理论与实践结合,不断积累成功经验,为推动行业进步贡献力量。